中文媒体说它是又一次升级。但代号 Spud 背后藏着一条没人提的线。
4 月 23 日发布,4 月 24 日 API 全开,节奏比往常快一天
4 月 23 日,OpenAI 官方发布页挂出 GPT-5.5,代号 Spud。第二天 API 全量开放,gpt-5.5 和 gpt-5.5-pro 两个版本同时上线。
发布页给的定位是"最智能、最直观的模型",主打四个方向:agentic coding(让模型自主写代码、跑代码、改代码)、computer use(操作电脑)、knowledge work、早期科研协作。Terminal-Bench 2.0 拿到 82.7 分,GDPval 84.9 分。系统卡和发布页同步更新,新增 API 上线后的额外安全约束。
X 上的官方主线把它形容成 "a new class of intelligence for real work and powering agents"。早期接入的近 200 个合作伙伴里,有人反馈说它更像"研究伙伴"。
听起来又是一次常规迭代——直到你回头看 OpenAI 过去一年发了什么。
5.1、5.2、5.3、5.4 都共用一套底,5.5 才是真正的换底
这一段是目前中文媒体几乎都没提到的事。
GPT-4.5 之后,OpenAI 一年多里陆续放出 5.0、5.1、5.2、5.3、5.4,外界默认每一个小数点后的版本号都是某种"升级"。但对照官方发布页和过往 release notes,会发现一个一直被掩盖的事实:5.x 家族里,5.5 之前的所有版本都是 post-training 迭代——也就是同一个预训练好的基座,反复做指令微调、做对齐、做工具调用训练得到的产物。
GPT-5.5 才是自 GPT-4.5 以来第一次完全重训练的新基座。
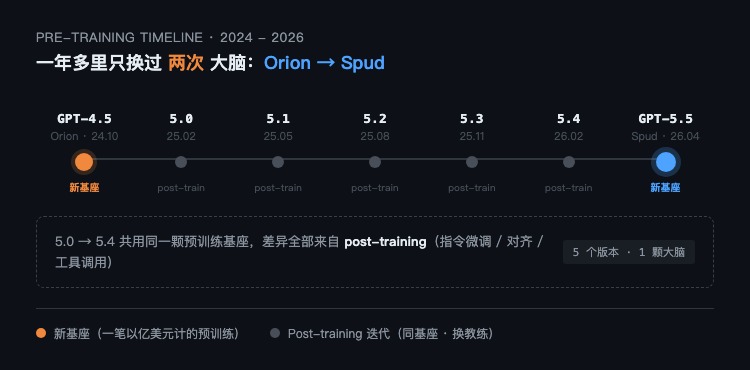
这件事在产品发布的语境里听起来像技术细节,实际上不是。预训练是一笔以亿美元计的开销,post-training 不是。这意味着 OpenAI 一年多里把账面上看起来很多的"新模型",全部摊在了同一次大预训练上。直到 Spud 出现,才重新启动了那台烧钱机器。
换句话说,市面上你看到的所有 5.x 模型,能力差异本质上都来自"换教练",不是"换大脑"。GPT-5.5 是这一年多里 OpenAI 第一次重新捏出一颗大脑。
这个角度也解释了一件事——为什么 OpenAI 这一年发布密度极高,但每次的能力跳跃都不算特别夸张。因为基座没变,post-training 能挤的水分总有上限。Spud 上来之后,分数一下子上了一个台阶,并不偶然。
更值得读的细节是,OpenAI 在发布页里并没有明确说 GPT-5.5 是"新基座"。这个信息散落在系统卡的训练数据截止时间(2025 年 8 月,比 5.4 晚了 6 个月)、新的 tokenizer 配置、以及合作伙伴的早期访问反馈里。把这几条线索拼起来,结论才浮出水面。这种处理方式本身就说明问题——预训练成本是 OpenAI 最不想被外界精确估算的数字之一。说"新基座"等于隐含告诉市场"这一次又烧了多少亿",不说,账面就还是漂亮的。
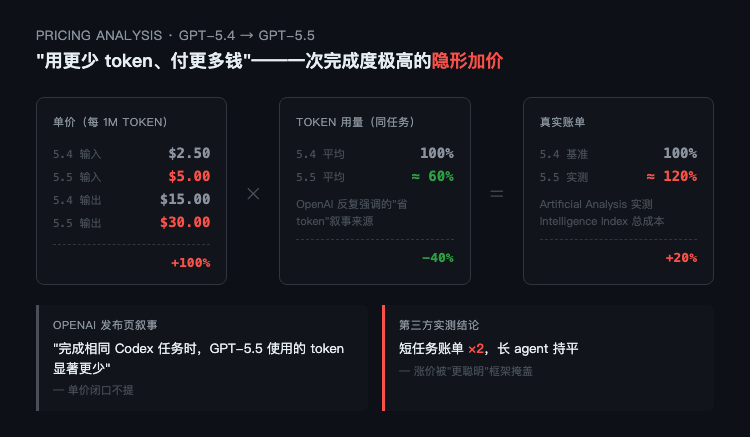
"用更少 token、付更多钱",OpenAI 完成了一次隐形加价
发布页里 OpenAI 反复强调一句话:完成相同 Codex 任务时,GPT-5.5 使用的 token 显著更少。X 主线也在重复这个叙事——更聪明、更高效、更省。
但发布页只字未提单价。
第三方评测机构 Artificial Analysis 把账算了出来。GPT-5.5 的 per-token 价格相比 GPT-5.4 直接翻倍——输入 5 美元、输出 30 美元(每百万 token)。与此同时,token 用量平均下降约 40%。两笔一相乘,跑完整个 Intelligence Index 的真实成本上涨大约 20%。
| +20% |
这就有意思了。
OpenAI 给出的话术框架是"省 token",读起来你会以为模型变便宜了。但 token 不是收银台,钱才是。把价格和用量放在一起算,得到的结论是这次发布整体涨价 20%。
更妙的地方在于,这个加价方式让用户很难抱怨。你不是被涨价了,你只是"用了更聪明的模型"。月底账单变大的时候,没人会觉得是单价在涨。
翻完目前能找到的中英文报道,几乎所有热文都在引用 OpenAI 自己的"更便宜"话术。Artificial Analysis 那张实测成本对比图被引用得很少。差额几乎没人拎出来看。
这是一次完成度很高的效率叙事——技术指标全是真的,但落到用户钱包里,方向是反的。
更隐蔽的一层在于场景差异。"省 token"这个红利只对长任务有效——一个跑半小时的 agent,5.5 可能用掉过去 60% 的 token,账单确实可能持平甚至略低。但短任务不一样。一次简单的分类调用,5.4 用 200 个 token,5.5 也得 150 个上下,因为 prompt 部分根本压不下去。这种场景下你拿到的是纯粹的单价翻倍。
换句话说,这次定价改动里隐藏了一次结构性的转移:把价格优势让给做 agent 的人,把成本上涨摊给做高频短任务的人。两类客户在 OpenAI 营收里的权重,正在被悄悄重排。这和 OpenAI 这一年的产品方向也是吻合的——Codex、Operator、Computer Use 这些 agent 产品全是高 token 消耗场景,OpenAI 想让生态向这边倾斜,定价杠杆就得这么调。
SWE-Bench Pro 一栏的脚注,是 OpenAI 第一次隐式指控友商
发布页里有一张大的 benchmark 对比表。GPT-5.5 在大部分项目上拿到第一。
但 SWE-Bench Pro 这一行不一样。Claude Opus 4.7 的分数比 GPT-5.5 高,OpenAI 没赢。
按惯例,这一栏要么不放,要么放完承认。但 OpenAI 选了第三种走法——在 Anthropic 那一格分数旁边加了一个脚注:
"Anthropic reported signs of memorization"(Anthropic 自己也报告了模型存在记忆痕迹)

在自己的发布页里、在自己的对比表里,给竞品分数加一行"它们这个数据可能有污染",这是相当少见的动作。它至少有三层信号:
第一,OpenAI 在 SWE-Bench Pro 这条线上接受了数字层面输给 Claude Opus 4.7,转而打"我们的 58.6 是干净的、它们的 64.3 不是"这种合规牌。
第二,把竞品的自我披露(Anthropic 自己说测试集可能被记住)当弹药用。这个脚注在事实层面无懈可击——它没有指控 Anthropic 主动作弊,只是引用了对方自己说过的话。
第三,这是一次相当克制的攻击。它没有出现在博客正文,没有出现在 X 主线,只埋在 benchmark 表的小字里。但只要有人认真读表,这个脚注就会让 Anthropic 在 SWE-Bench Pro 上的领先看起来含糊。
这条信号比 ARC-AGI-2 上 +11.7 分的领先更值得读。它说明 OpenAI 已经开始把"测试集干净度"当作一条新的竞争维度。比拼数字不再是唯一战场——数字的可信度也是。
往前回想一下,过去两年大模型 benchmark 战争的常见戏码是这样的:A 公司发布,超过 B 公司 5 分;下个月 B 公司发布,又反超 4 分。读者看到的全是绝对数字,没人深究测试集污染、训练数据截止时间、跑分时的 system prompt 设置。这次 OpenAI 把"对方自己承认了记忆痕迹"这件事公开摆在表里,等于在 benchmark 战争里开了一道新的口子。
接下来如果 Anthropic、Google、xAI 任何一家发布新模型,都得提前想好——你的训练数据有没有意外吃进 SWE-Bench Pro 的题面,你愿不愿意像 Anthropic 那样自我披露,披露之后会不会被对手当成脚注引用。这件事的连锁影响,比 GPT-5.5 本身的能力跳跃还要长远。
Spud 之后,下一颗大脑要等到 GPT-6.5
把这三件事拼在一起,能看到一个比"GPT-5.5 发布"大得多的故事。
OpenAI 用一颗新基座配上一套"看似变便宜"的定价,重新拉开了 5.x 家族的成本上限。预训练这笔大账,估计还要在接下来的一年里继续摊给 5.6、5.7、5.8——历史会重复。Spud 之后,下一颗真正的大脑大概要等到 6.5 才会出现。
对开发者最实际的几个判断:
做长任务 agent 的:如果你在做 computer use、需要大量工具调用的场景,可以试 5.5——能力提升在这一类任务上最明显,token 节省也大概率能抵消单价。Terminal-Bench 2.0 上 82.7 分对应的是模型能在终端里连续跑几十步操作不崩,这个跳跃值得切。
做高频短任务的:如果你做的是批量 embedding、客服话术分类、文本审核这类短上下文、对成本敏感的应用,不要急着切。这次发布的"省 token"红利在你这种场景里几乎兑现不了,账单会直接涨 100%。在这类场景里,5.4 甚至 5.3 还会是更好的性价比选项——OpenAI 没说要下线它们,但历史上"老版本被悄悄涨价或限速"的情况发生过不止一次,建议早做迁移评估。
读 benchmark 的所有人:SWE-Bench Pro 的那个脚注提醒你,benchmark 已经进入了"既看数字也看出处"的阶段。下次再有公司宣称在某个评测上拿到第一,请先看脚注。
最后留一个观察。GPT-5.5 的代号是 Spud,土豆。这个内部代号在系统卡里露过几次。OpenAI 这一代命名风格越来越像研究项目而不是产品——上一颗真正的新基座(GPT-4.5)内部代号是 Orion。从 Orion 到 Spud,发布姿态明显放低了。这或许是 OpenAI 自己也意识到——预训练这条路上,每一颗新大脑能拉出来的领先优势,正在变得越来越小。
这里是费曼比特,每一个观点都追溯到一行源码、一段论文、或一个数据。
数据来源:
OpenAI 官方发布页 Introducing GPT-5.5:https://openai.com/index/introducing-gpt-5-5/
GPT-5.5 System Card:https://openai.com/index/gpt-5-5-system-card/
OpenAI Deployment Safety Hub - GPT-5.5:https://deploymentsafety.openai.com/gpt-5-5
Artificial Analysis 第三方实测:https://artificialanalysis.ai/articles/openai-gpt5-5-is-the-new-leading-AI-model
OpenAI 官方 X 发布主线:https://x.com/OpenAI



网友评论